Why R (and not excel anymore)

Hi 👋, and welcome to my first post. A first post on a blog might be similar to the first article being published. It feels like a long and stony way but you are super satisfied after you successfully managed to get it done. Two things paved my way for this site and my first post:
First Corona hit everybody hard in Europe and the world in early 2020. Specifically in my case, I spent even more time in home-office than before and lab work was forced to rest. What to do? This was the starting point to use my time and learn R. What should I say…since then, I absolutely fell in love with it 😍
Second A colleague (Harald) had the idea to create a “redox-net”, a panel to exchange about redox measurements in soils (to say it with his words in german: “um einen Pflock einzuschlagen”).
So…here we are 😄
I will give you five reasons to learn R and employ it for your environmental studies, in contrast of using excel anymore (my impression and in random order).
1. A script in R will win over embedded formulas in excel
What does this mean. Well, this is a super simple example but imagine you want to calculate the mean from a time series of EH measurements. In excel, your formula to do so is embedded within the cell and not visible for peers. If you have complicated multi-step tasks to solve this is hard to digest.

The user interface of R (or from RStudio, which is a development environment for R) works different. You have both the ability to write code and comment at each step what your are doing.
# This command reads the data
df <- readr::read_delim("data.csv", delim = ";",
col_types =
cols(
# This command tells R to format the time column
time = col_datetime(format = "%d.%m.%Y %T")
))
# This command calculates the mean and the standard deviation from the column value
df %>%
summarise(mean_ts = mean(eh_001),
sd_ts = sd(eh_001))## # A tibble: 1 x 2
## mean_ts sd_ts
## <dbl> <dbl>
## 1 5.5 3.03Your comments in R are separated from the code with #. So when you run the code, it will neglect all parts that start with #. Et voila, you calculated your value with 5.5 ± 3.03 🎉
You think “I am still faster in excel”? 🤷️ One of the superpowers of R comes into play if you have up to 1000 columns that contain a distinct character in their column names (most of my posts will be about redox so let’s assume you have time series data of 10 redox channels (or a thousand more) from a data logger labeled from eh_001 to eh_010). By adjusting the code above to:
# Calculate the summary statistics with the mean, standard deviation (sd),
# minimum (min) and maximum (max)
# for the columns from eh_001 to eh_010
df %>%
summarise_at(vars(eh_001:eh_010), list(mean = mean,
sd = sd,
min = min,
max = max)) %>% head()## # A tibble: 1 x 40
## eh_001_mean eh_002_mean eh_003_mean eh_004_mean eh_005_mean eh_006_mean
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 5.5 6.5 7.5 8.5 9.5 10.5
## # ... with 34 more variables: eh_007_mean <dbl>, eh_008_mean <dbl>,
## # eh_009_mean <dbl>, eh_010_mean <dbl>, eh_001_sd <dbl>, eh_002_sd <dbl>,
## # eh_003_sd <dbl>, eh_004_sd <dbl>, eh_005_sd <dbl>, eh_006_sd <dbl>,
## # eh_007_sd <dbl>, eh_008_sd <dbl>, eh_009_sd <dbl>, eh_010_sd <dbl>,
## # eh_001_min <dbl>, eh_002_min <dbl>, eh_003_min <dbl>, eh_004_min <dbl>,
## # eh_005_min <dbl>, eh_006_min <dbl>, eh_007_min <dbl>, eh_008_min <dbl>,
## # eh_009_min <dbl>, eh_010_min <dbl>, eh_001_max <dbl>, eh_002_max <dbl>, ...This gives you the summary statistics of all your 10 channels. It looks awkward right now but there are various ways to create beautiful tables from this data frame (or more precisely called a tibble in R). Your are impressed? We can make it even shorter with:
# Plot the summary statistics for the data table "df" including all channels
summary(df)## time eh_001 eh_002 eh_003
## Min. :2021-02-09 00:00:00 Min. : 1.00 Min. : 2.00 Min. : 3.00
## 1st Qu.:2021-02-11 06:00:00 1st Qu.: 3.25 1st Qu.: 4.25 1st Qu.: 5.25
## Median :2021-02-13 12:00:00 Median : 5.50 Median : 6.50 Median : 7.50
## Mean :2021-02-13 12:00:00 Mean : 5.50 Mean : 6.50 Mean : 7.50
## 3rd Qu.:2021-02-15 18:00:00 3rd Qu.: 7.75 3rd Qu.: 8.75 3rd Qu.: 9.75
## Max. :2021-02-18 00:00:00 Max. :10.00 Max. :11.00 Max. :12.00
## eh_004 eh_005 eh_006 eh_007
## Min. : 4.00 Min. : 5.00 Min. : 6.00 Min. : 7.00
## 1st Qu.: 6.25 1st Qu.: 7.25 1st Qu.: 8.25 1st Qu.: 9.25
## Median : 8.50 Median : 9.50 Median :10.50 Median :11.50
## Mean : 8.50 Mean : 9.50 Mean :10.50 Mean :11.50
## 3rd Qu.:10.75 3rd Qu.:11.75 3rd Qu.:12.75 3rd Qu.:13.75
## Max. :13.00 Max. :14.00 Max. :15.00 Max. :16.00
## eh_008 eh_009 eh_010
## Min. : 8.00 Min. : 9.00 Min. :10.00
## 1st Qu.:10.25 1st Qu.:11.25 1st Qu.:12.25
## Median :12.50 Median :13.50 Median :14.50
## Mean :12.50 Mean :13.50 Mean :14.50
## 3rd Qu.:14.75 3rd Qu.:15.75 3rd Qu.:16.75
## Max. :17.00 Max. :18.00 Max. :19.00Boom … 💪 summary(XY)will give you everything you want to have. It is as simple as pretty.
2. Speed up your reporting
Delivering a report to your boss or co-authors and update them about a running experiment is a common task. However, if the origin of your data changes, e.g. your time series of the experiment develops, you are in trouble if you have to do the report on a weekly basis. Doing the statistics and the visualisation in excel, export the graphics to a word document, and finally comment the outcome will take some time. Why has the use of R advantages:
The rmarkdown package enables a dynamic reporting where you can include the so-called “code chunks” (in between the notation ```{r} ````) and comment on them (see below).
Everytime you change the data and run the script, it will automatically update each and every figure or summary table.
Trust me, if you have time series data up to 10 years from 50 channels you can end up easily with ~200k observations. rmarkdown makes reporting way easier if you, for instance, want to include the 11th year from your field measurements.

rmarkdown
3. A package for everybody
The community of R users is steadily growing and with this development the amount a packages is growing as well. What is a package? To state it with Hadley Wickhams words (he is chief-scientist at RStudio and one of the main reasons why RStudio became so popular):
“An R package is a collection of functions, data, and documentation that extends the capabilities of base R. Using packages is key to the successful use of R.”
(from r4ds)
I guess the book r4ds is the bible for data scientists just as is the Bodenkundliche Kartieranleitung (source: Wikipedia) for soil scientists in Germany 😄
One example to highlight what I mean:
The Penman-Monteith equation is used to calculate the reference evapotranspiration according to FAO. A variety of meteorological parameters are included inside the equation, which makes it highly vulnerable if you do the calculation manually (e.g. with excel) (source: Wikipedia).

Fortunately, the Evapotranspiration package Link enables modeling of actual, potential and reference crop evapotranspiration. Implementing the script and functions within the package potentially reduces the possibility for errors, while simultaneously enhancing flexibility in the choice of your model.
4. Customize your (multipanel) plots
We have already seen an example of a created plot above. I think it is amazing how flexible you are to customize your plots. The most popular package is called ggplot2. You can easily manipulate your labels and titles, scale your x- and y-axis, try different geoms, and so on. I greatly recommend the contribution from Cédric Scherer on beautiful plotting in R and the evolution of a ggplot to get an impression what I am talking about 🔥
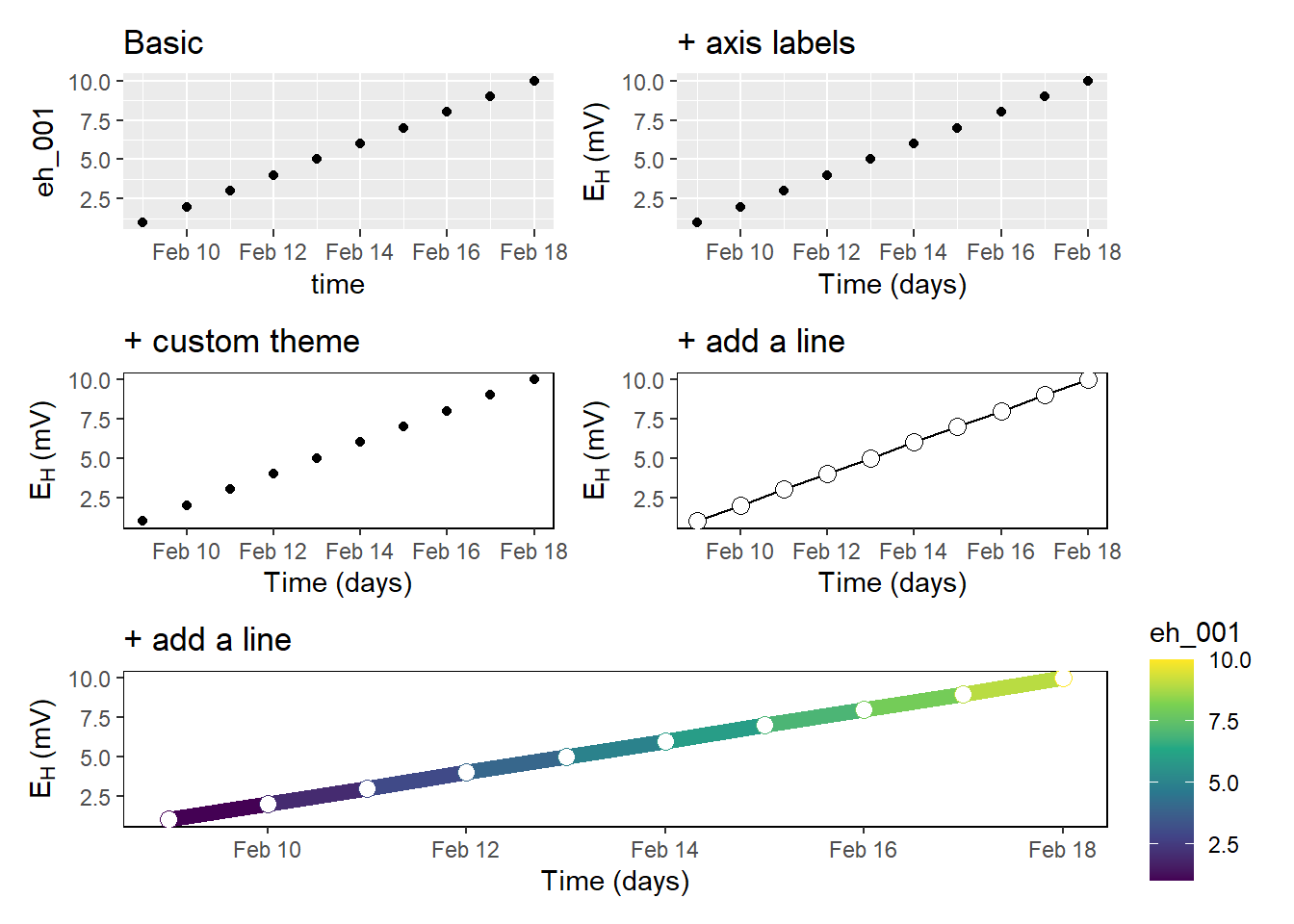
Previously, I worked with a different visualisation software and the alignment of multipanel plots was tedious and cumbersome. However, the package patchwork in R makes the arrangement of multiple plots so easy that it still makes me smile.
5. Spent your money for charity, vacations, or whatever you desire
Tools for exploratory data analysis and visualization usually cost a lot of money. Sometimes you do not even get a full license but instead only a 1-year permission to use a certain software. R is, and as far as I can tell will be, free of charge and I think this makes it highly versatile to learn it. If you move the company or position at university, you might lose the permission of a software you are already used to. This will not happen if you can take your R and RStudio software and re-download it as often as you want. In addition, there are a variety of sources and platforms who offer support if you run into trouble with your R project. One platform where you can find help is the site stackoverflow. From my experience, the community is super fast, friendly and will offer help for your very specific R problems.
Overall, these are my individual top five why I think R is a thing you should keep in mind for doing your exploratory data analysis over excel. I hope you liked it and would love to hear your thoughts.
Cheers
Kristof
Kristof Dorau
Research assistant
My research interests include redox dynamics in soils, environmental monitoring and recently data analysis in R.